「このシステムは今いるメンバーは誰もよくわからない」から始める、予測可能性を高めて不安とリスクを制御する オブザーバビリティ の実践的アプローチ
システムをいい感じに、不安少なく楽しく運用していくのはオブザーバビリティが効くらしいぞ。なにやら属人性を下げて・変更に強く・障害から素早く回復できるようになるらしいぞ。と主張するのがこの記事の趣旨です。
ことのおこり
主要ではないし動作も性能も安定しているから最近活発に手を入れてなかったから、わかるひとがほとんど居ない。だけど確かにユーザーは利用していて、ないと困る。そんなシステムやサブシステム、よくありますよね。
さて、チームでこんな会話を耳にしたことはないでしょうか。
「このシステムは、Aさんに聞かないとわからない」「詳しい人がもういないんですよね…」
特定の個人に負担が集中し、結果として知識と経験が集中する。すると、ひとり(あるいはごく少数)がいなくなると、もう全くわからない。いわゆるバス係数が小さい状態になってしまう。
これは多くの組織が抱える、非常によくある課題です。
しかし効率を考えると「わかる」人に任せて手早く質高く、つまりコスト・リスクを小さく済ませたいわけです。しかし効率を考えて特定のメンバーに対応を寄せると、早晩「あの人しかわからない」が発生します。このような「わからない」状態はそのままにしておくと属人化を加速させ、結果的にチームの成長を阻害し、チームを疲弊させてしまいます。困りますね。なんとかなって欲しいと祈りたい気持ちになります。
SREの世界では「Hope is not a strategy」という格言があります。人事を尽くさずに祈るのはアカンというわけです。
今回の記事では、この「わからない」に向き合い、乗り越えていくきっかけになる話をします。
目指すのは、チームのエンジニアであれば誰でも「いまのところよく知らないけれど、まあなんとかなるだろう」と言える状況です。
「わからない」という現実を、チームで受け入れるところから始めよう
まず大切なのは、この「わからない」という状態を否定しないことです。現状は健全な努力や効率化の結果の状態ですから、誰が悪いわけでも無能なわけでもありません。往々にして、それぞれがベターな選択をした結果なわけです。
ですから、まずはありのままを素直に受け止めます。たとえ書類上は解決しているはずのことが実態解決していなくても、それを現実として認めるのが初手になります。
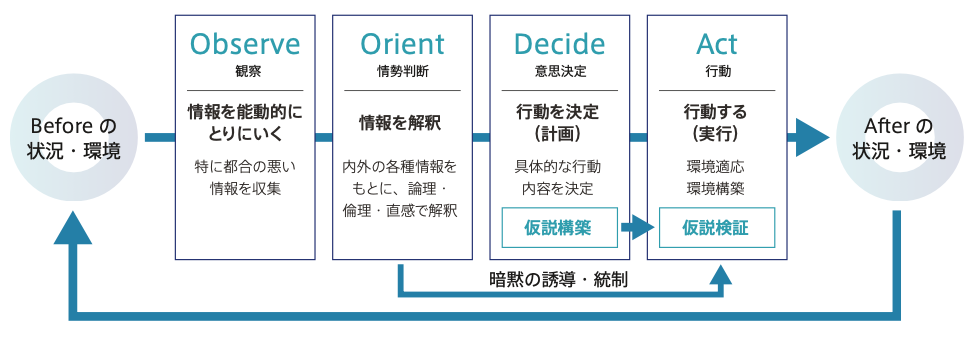
このような改善の取り組みでは、わたしはOODAループの考え方を推奨しています。都合がよくない情報をいち早く収集して、迅速に状況を変える行動を起こすのが肝心です。PDCAのように計画を重視し計画とのアラインメントを軸にはせず、観察からの仮説検証を軸にします。
迅速な継続的改善活動の考え方のひとつにOODAループ(ウーダループ)があります。
Observe→Orient→Decide→Actを高速に回すことで状況変化をいち早く掴み、迅速な適応行動やこち らからの先んじたアプローチを実現する考え方です。この変化アジリティ重視のアプローチは現代のシ ステム運用現場にとてもよく適合します。
このように改善活動の入り口は情報収集で、何かを継続的・計画的に改善し続けるとき土台になるのは計測 です。状態を観測して数値化し、時系列で比較可能にすることで、効果測定ができるようになります。
SEE ALSO:
繰り返しますが、システムが「よく分からなくなる」のは、ほとんどの場合において誰かの怠慢や力不足、失敗、悪意の結果ではありません。いわゆる技術的負債と同じで、その時々でそれぞれの持ち場で妥当な判断と行動を尽くした結果として、必然的に発生してしまう「システムの経年劣化」のようなもので、健全な組織活動の結果として起こりうることです。
だからこそ「わからない」を恥ずかしいことや隠すべきことと捉えるのではなく、チームで向き合うべき現実として受け入れる。その受容の態度がスタート地点です。
ドキュメントは頼もしいけれど頼りにはならない
「ドキュメントを見ればいいじゃないか」と思われるかもしれません。しかし、現実はどうでしょうか。
- 作成時点では正確だったが、その後の変更が反映されていない
- 書いた人の視点・視野が前提になっていて、他の人が読んでも全体像が見えない
- そもそも存在しない、またはどこにあるか見つけられない
いずれもよくあるパターンです。
これもまた、誰かを責めるべき問題ではありません。限られたリソースの中で、動くコードを優先するのは合理的な判断です。しかし結果として、ドキュメントは「書いた人のため」の、「書かれた瞬間のスナップショット」になり、動き続けるシステムそのものを表現しきれないのです。
なおこのあたりのドキュメントは、(少なくともソースコードの内部構造については)いい感じに生成AIの支援を受けられるようになり、更新や理解が捗るようになってきています。
「わからない」がもたらす、見過ごせない心理的負担
システムが「わからない」状態は、単に技術的な問題だけではありません。チームに大きな心理的負担をもたらします。
- 障害が起きたときに「原因がわからないかもしれない」という不安
- 利用者に挙動を聞かれたときに「よくわかりません」と回答する不安
- 変更を加えるときに「何か壊してしまうかもしれない」という恐怖
- 深夜や休日に、いつ呼び出されるかわからないというストレス
- 新しいメンバーに「うまく説明できない」という申し訳なさ
これらの負担は、チームの「心理的安全性」を著しく損ないます。そして、心理的安全性が低い環境では、メンバーはなにかにつけて挑戦を避け、結果として技術的負債がさらに積み上がっていくという負のスパイラルに陥りがちです。
このような状況を打破するにはリーダー / マネージャーレベルの裁量と権限が必要です。
2つのアプローチ:「わからないまま扱う」と「少しずつわかるようにする」
では、この厄介な「わからない」と、私たちはどう向き合っていけば良いのでしょうか。
わたしはアプローチは大きく2つあると考えています。それは、「わからないまま扱う」ことと、「少しずつわかるようにしていく」ことです。これらは対立するものではなく、併用します。
繰り返しますが、目指すのはチームのエンジニアであれば誰でも「いまのところよく知らないけれど、まあなんとかなるだろう」と言える状況です。
アプローチ1:「わからないまま」扱う技術
これはシステムの内部がブラックボックスであることを一旦受け入れた上で、その外側から振る舞いを観測し、制御するアプローチです。
具体的には、以下のような方法があります。
- 外形的な監視:レイテンシーやエラーレートといった利用状況の指標を計測し、その変化を捉える
- 稼働データ分析:クラウドサービスや監視ツール、オブザーバビリティツールを導入するとデフォルトで取得される多くの指標を計測し、その変化を捉える
- ログ分析:アプリケーションやインフラが出力するログから、パターンや異常の兆候を見つける
内部の挙動を把握してボトムアップで挙動を理解するアプローチは一旦忘れて、できることから着実に改善していく。これも立派な戦略です。ただし対症療法に陥りがちになるという側面も理解しておく必要があります。
なお、監視は継続的なテストでもありますから、これからシステムに向き合っていくために不可欠なものです。テストコードがないのに改修やリファクタリングはできないですよね。
アプローチ2:「少しずつわかる」ようにしていく技術
もう一つのアプローチは、ブラックボックスの蓋を少しずつ開けて、中を覗き、理解していくことです。
このアプローチを強力に後押しするのが、前述の監視に加えて、「オブザーバビリティ」(Observability:可観測性)の考え方です。特にトレースやAPM(Application Performance Management)が直接的に効果があります。
オブザーバビリティを高めると、以下のようなことが驚くほど詳細に可視化できます。
- 個々のリクエストがシステムの内部でどのように処理され、どのくらい時間がかかっているのか ➔トレース
- このシステムがどの外部コンポーネントや外部システムとどのくらい通信しているのか ➔サービスマップ
APMは既存のコードを全く(あるいはほとんど)変更せずに初期導入できるものが多く、ブラックボックスを少しずつ解きほぐしていくアプローチに最適です。コードだけでは確信が持てない実際の挙動を見てひとつひとつ「わかる」に変えていく。この「データによる裏取り」が、「少しわかる」体験を積み上げます。
想定したシーケンス図が実際のシステム上でその通りになっているか確認できるのは非常に心強いですよね。特にアプリケーション開発者やマネージャー向けに、既刊ホワイトペーパー『インフラ用語少なめのオブザーバビリティ入門ガイド』を書きましたので、ぜひご参照ください。

「自信と確信」を育む具体的なアクション
また繰り返しますが、目指すのはチームのエンジニアであれば誰でも「いまのところよく知らないけれど、まあなんとかなるだろう」と言える状況です。
2つのアプローチ、監視とオブザーバビリティによって変革の準備ができます。
そのうえで重要なのは、監視ツールやオブザーバビリティツールから得られるデータをチームの共通言語とし、対話し、改善に繋げる習慣を育てることです。
端的に「OODAループを回そう」という話ではありますが、それだけではありません。
リーダーやマネージャーの役割には、ツールを提供することに加えて、「場」と「関係性」をデザインすることもあります。
アクション1:「定点観測会」で普段からシステムに触れる
障害が起きたときだけデータを見ても、それが異変なのかいつも通りなのかわかりません。
データ的には不具合を誘発してもおかしくない値だが、いつも通りの別の障害の原因ではあるものの、今回特別に顕在化した障害の要因ではないという場合もあります。
Note:通常と正常と異常
語 意図 異常だが通常 いつもシステム利用に支障がある 異常だが正常 システムの状態はいつもと異なるがシステム利用に支障はない 通常だが異常 システムの状態はいつもどおりだがシステム利用に支障がある 通常で正常 システムの状態がいつもどおりでシステム利用に支障がない 正常で異常 システム利用に支障はないがシステムの状態はいつもと異なる 正常で通常 システム利用に支障がなくシステムの状態はいつもどおり

通常を知っておくと、いざデータを見たときに振り回されることが少なくなり安心してデータを見ることができます。そこで私が強く推奨しているのが、「定点観測会」です。
週に一度、15分でも30分でも良いので、チーム全員で主要なダッシュボードを眺める時間を設ける。これを続けることで、チーム全体が「このシステムの通常状態」を肌感覚で理解できるようになります。
そして何より重要なのは、これが心理的な距離を縮め「データで対話する文化」の第一歩になることです。定期開催により接触回数を増やすこと、心理的安全性を確保し建設的な場にすることが非常に重要で、場と安全性を通じて技能や知識、価値の認識/価値観、コンテキストなどを共有します。
そうしてOODAループのサイクルを繰り返すことで、特にOODAループにおけるObserve(観察)とOrient(情勢判断)の質をチーム全体で高めます。
アクション2:ポストモーテムを「学びと改善のサイクル」に変える
定常的な活動の次は突発的な活動についてです。
障害(インシデント)は、最高の「学びの機会」です。なんとしても発展と前進の機会にしましょう。
わたしのお勧めは、SREのプラクティスで「ポストモーテム」と呼ばれる事後分析の取り組み(およびドキュメント)です。
似た領域の取り組み(およびドキュメント)に障害報告がありますが、障害報告とポストモーテムは大きく異なります。
- 障害報告: 経緯や結果を明らかにし、顧客や上長などチーム外への説明責任を果たすための取り組み(およびドキュメント)
- ポストモーテム: 現在・未来のチームメンバーなどの関係者のための、建設的にことにあたるための取り組み(およびドキュメント)
障害対応を経て、メンバーはシステムにかなり詳しくなるでしょう。
最も重要なのはポストモーテムで得られた知見を今後に活かすことです。それはコードの改善であったり、テストコードや監視の追加であったり、ダッシュボードの更新であったり、運用ルールの更新であったりします。
この「障害→学習→改善」というサイクルを回し続けると、チームの「自信と確信」が育っていきます。
ポストモーテム活動においても「場」と「関係性」のデザインはものすごく重要です。ポストモーテムは特に障害報告的になり懺悔や謝罪の方向に行きがちですが、そうならないよう、建設的かつ客観的に取り組むように仕向け、ハンドリングします。
より詳しくはわたしが書いた『バックエンドエンジニアのためのインフラ・クラウド大全』14章8節「学習・予防を豊かにする事後分析:ポストモーテム」をご参照ください。

「自信と確信」を育むためのリーダーの役割
さて、ここまで技術的なアプローチを中心に話してきましたが、最後にリーダーやマネージャーの職務的な期待役割について触れたいと思います。
それは端的に投資する覚悟と意思決定です。
リーダーやマネージャーから見ると、メンバーの属人性の高さや、メンバーの健全性・楽しさ・不安は主にパフォーマンスと持続性の観点でのパフォーマンスチューニングとリスクマネージメントです。
リスクマネージメントの手法は主に保有(受容)/ 回避 / 低減 / 移転です。
この記事を読んでいただいているということは、持続性のリスクが高まっているということでしょう。ブラックボックスなシステムで困っていて対策したいということは、保有戦術を切り替えるタイミングに来たという証です。
放置していたシステムを触ったり、オブザーバビリティツールを導入するには、工数と費用がかかります。工数配分やツールに投資するかどうか、つまりリスクをこのまま保有するのか、それとも低減などに取り組むのか、意思決定する時が来たということです。そして、その意思決定をするのがあなたというわけです。
次のような効果が期待できる投資です。システムの、チーム / 組織の持続性に効きそうですね。
- 属人化の解消による組織リスクの低減
- 障害対応時間の短縮による機会損失の削減
- エンジニアの心理的負担軽減による生産性向上と離職率低下
まとめ:最初の一歩を踏み出す
長くなりましたが、最後にまとめです。
システムの「わからない」は、避けられない現実です。しかし、それは乗り越えられない壁ではありません。適切なアプローチとツール、そして何より「わからないを受け入れる文化」があれば、チームは確実に前進できます。
監視やオブザーバビリティの実装がなければそこから、多少なりともあれば週一回の定点観測会でそれらを眺めるところから、始めてみてはいかがでしょうか。
これらの実践を通じて、チームの「不安」が「自信と確信」に変わっていく様子を、ぜひ体験していただきたいです。
参考:

