AIエージェントを実務に活かすために、まず評価の仕組みを作った話
はじめに
生成AIを自分たちの業務にどう取り入れるかは、もはや当たり前に議論される話題になっています。
一方で、実務で使う立場から見ると、「結局どのツールが一番良いのか」にとどまらず、次のような問いも浮かんできます。
- どの業務なら AIエージェントに任せられるのか
- どの条件であれば、一定の品質を再現できるのか
- 生成結果をどう評価し、どう改善につなげるのか
- 社内で継続的に使うために、どのような手順やガードレールが必要か
今回、私たちはコード生成を題材に、Claude CodeとGitHub Copilotの比較検証を行いました。
ただし、単にツール同士を比べることが目的ではありません。
目的は、AIエージェントを実務に入れていくための評価フレームワークを作ることでした。
この記事では、評価フレームワークの整備から、実際の比較検証、そしてフレームワーク自体の改善サイクルまでを通じて見えてきたことを整理します。
重要だったのは、評価設計と運用設計、そしてそれを回し続ける仕組みでした。
この記事で扱うこと
- AIエージェントの業務活用に向けて、どのような評価フレームワークを整備したか
- コード生成を題材に、どのような観点で実務適性を確認したか
- 評価フレームワーク自体を改善し、再評価することで見えてきた知見
- カスタムインストラクションの効果と、その設計で気をつけるべきこと
背景
この取り組みの出発点は、LLM(大規模言語モデル)を単なる便利なツールとして扱うのではなく、業務の一部を担う存在として扱えるかを確かめたい、という問題意識でした。
AIを組織として活用するには、個人がプロンプトを工夫して便利に使うだけでは不十分です。
どの業務を対象にし、どの品質基準で評価し、どこまで任せてよいのかを、組織として見極める必要があります。
そこで今回は、題材としてAnsibleのコード生成を選びました。
Ansibleはインフラの構成管理を自動化するツールで、記述の正確さや一貫性が厳しく問われるため、AIエージェントの実務適性を測りやすい題材です。
単にYAMLの構文が合っているかどうかだけでなく、次のような観点でAIの実務能力の深さを測ることができます。
- 冪等性が保たれているか
- モジュール選択が適切か
- Role構成や変数設計に破綻がないか
- ansible-lint(以下Lint)に準拠した記述が行えるか
- エラーを含むPlaybook(Ansible の設定ファイル)を修正できるか
今回やったこと
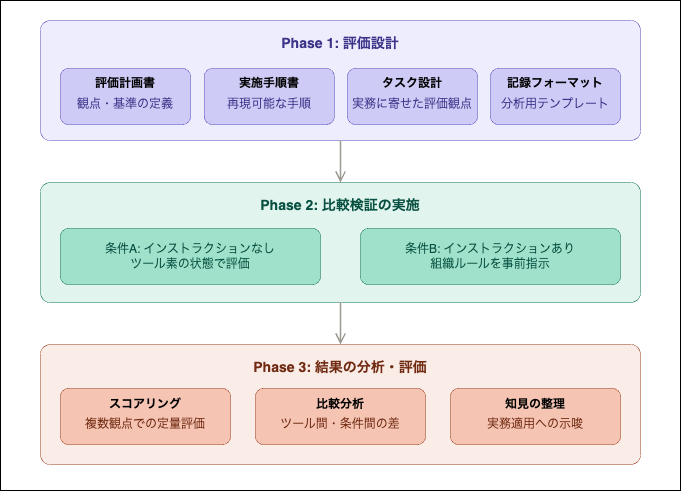
1. 比較の前に、評価の枠組みを作った
いきなりツールを触って感触を比べるのではなく、最初に評価の枠組みを整えました。具体的には、以下の成果物を先に作成しています。
- 評価計画書
- 実施手順書
- 分析手順書
- 結果記録フォーマット
- タスク別プロンプト
この時点で重視したのは、誰が実施しても同じ手順で比較できることです。「なんとなく使ってみたら良さそうだった」では、社内資産になりません。
次回、別のツールや別の題材を評価するときにも再利用できる形にする必要がありました。
2. AIエージェントでたたき台を作り、人がレビューした
この評価基盤づくり自体にも、AIエージェントを活用しました。
以下のように複数のAIエージェントに異なる役割を割り当てて協調させる仕組みを利用しています。
- リサーチ結果の統合
- 主張のファクトチェック
- 評価計画書の構成設計
- 実施手順の文書化
- 独立したQAレビュー
ここでいくつかの気づきがありました。
AIエージェントは、ゼロからの初稿作成や論点の整理にはかなり有効です。
一方で、そのまま完成品として使えるわけではなく、実際に運用してみると手順の重複、命名のブレ、環境前提の抜けなどが見つかりました。
AIエージェントは設計や文書化の速度を上げる一方で、最終的な品質保証の責任までは引き取ってくれません。この前提は、コード生成でもドキュメント生成でも共通でした。
どのように評価したか
今回の比較では、Claude CodeとGitHub Copilotを対象に、Ansibleの実務でよくある作業をタスク化しました。
なお、両ツールとも同一のClaude Sonnet 4.6モデルを使用しています。
今回の評価は、モデルの性能比較ではなく、エージェントワークフローの差異がコード生成品質にどう影響するかを見る設計です。
評価結果は特定の環境・タスク・時点での検証に基づくものであり、ツールの一般的な優劣を示すものではありません。
評価対象は大きく次の 7 種類です。
- 自然言語から単一Playbookを生成する
- Role構成を含めて生成する
- 既存PlaybookをRole構成化する
- 既存のシェルスクリプトをAnsibleに変換する
- アンチパターンを含むPlaybookを修正する
- 冪等性を横断的に確認する
- 意図的に壊したPlaybookをデバッグする
評価観点は、単なる見た目ではなく、できるだけ実務寄りに置きました。
- 実行成功(Playbookが正常に完了するか)
- 冪等性(2回目の実行で changed=0 になるか)
- 動作確認(期待する状態になっているか)
- Lint通過状況(moderate / production プロファイル)
- 保守性(変数設計、Role構成、可読性、shell/command の回避)
また、比較条件として次の 2 パターンを用意しました。
- 条件A: カスタムインストラクションなし(素の状態)
- 条件B: カスタムインストラクションあり
条件Bでは、per-taskのbecome適用、Role変数プレフィックスの付与、Dockerテスト環境の制約事項など、組織ルールや環境条件に合わせた指示を事前に与え、ツールの追従性を評価しました。
こうした指示を条件として切り出しておくことで、単一の基準に留まらない、実務に即した柔軟な評価を可能にしています。
これは今回の検証に限らず、今後別のツールや題材を評価する際にも、組織固有のルールを差し替えるだけで同じ枠組みを再利用できるようにするための施策でもあります。
評価フレームワーク自体を改善した話
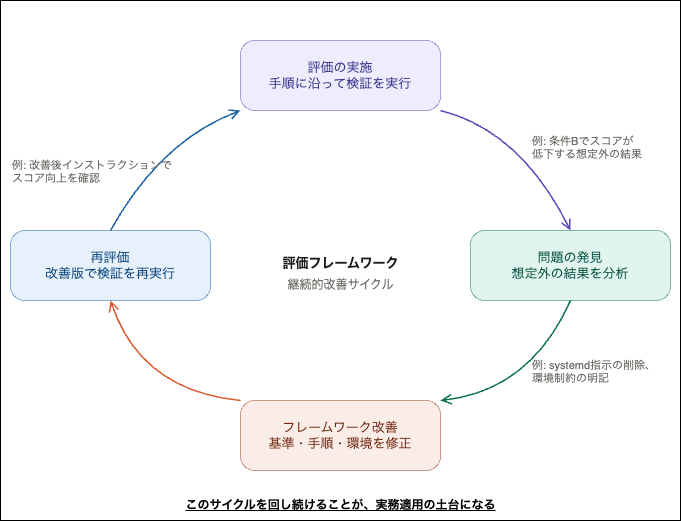
比較検証は一度では終わりませんでした。
初回の評価では、カスタムインストラクションを追加した条件Bで、両ツールともスコアが下がるという結果になりました。
ルールを丁寧に与えれば品質は上がるだろうという予想に反して、逆効果が出ました。
原因を調べたところ、インストラクションの中に含めた ansible.builtin.systemd の利用方針と、テスト環境のDockerコンテナが整合していなかったことが分かりました。
Dockerコンテナ内では完全な systemd が動いていないため、サービス起動系のタスクが失敗しやすくなっていたのです。
条件Aでは、両ツールとも ansible.builtin.service を自律的に選択して成功していました。
余計な指示を足したことで、かえってツールの適切な判断を上書きしてしまっていたわけです。
この結果を踏まえ、私たちは次のように改善しました。
- 環境と整合しない指示(systemd の強制)を削除
- テスト環境の制約事項をインストラクションに明記
- 効果が見込める指示を強調(per-task、become、Role変数プレフィックス、Docker環境対応など)
そのうえで、改善したフレームワークを使って再評価を実施しました。
この「評価 → 問題の発見 → フレームワークの改善 → 再評価」というサイクルを回せたこと自体が、今回のプロジェクトの大きな成果でした。
再評価で見えたこと
条件Aでは、両ツールの差はほぼなかった
各タスクは100点満点で採点し、実行成功・冪等性・Lint準拠・保守性などの観点を重みづけして合算しています。条件A(カスタムインストラクションなし)での平均スコアは、Claude Codeが 71.8点、GitHub Copilotが 71.5点でした。差はわずか 0.3点です。
特に印象的だったのは、最も基礎的なタスク(Task 1: 単一Playbook生成)で、両ツールが完全に同一のコードを生成したことです。 Play名、タスク名、モジュール選択、パラメータ、ハンドラー構成、インデントまで一致しました。
同じモデルを使っている以上、単純なタスクではツール間の差がほぼゼロになる。
これは直感的には納得できる結果ですが、実測で裏付けられたことには意味がありました。
カスタムインストラクションの効果
フレームワークを改善した結果、条件Bでの平均スコアはClaude Codeが 80.1点、GitHub Copilotが 75.8点となり、両ツールとも条件Aを上回りました。
初回の評価では逆効果だったカスタムインストラクションが、環境と整合するよう修正したことで、期待通りの効果を発揮しました。
ここで重要なのは、「カスタムインストラクションは効果がある」という結論だけではありません。
初回の失敗があったからこそ、どの条件で効果があり、どの条件で逆効果になるのかを切り分けられたということです。
インストラクション遵守能力には差があった
条件Bでの平均スコア改善幅は、Claude Codeが +6.3点、GitHub Copilotが +3.0点でした。これを5タスク合計で見ると、Claude Codeが +31.7点、GitHub Copilotが +15.0点でした。
差が顕著に出たのは、複雑なタスクにおけるインストラクションの遵守です。
たとえば Task 2(Role構成生成)の条件Bでは、Claude Codeがスコアを大きく伸ばした一方で、GitHub Copilotは伸び悩み、両者の間に大きな差が開きました。
Claude CodeはRole変数に適切なプレフィックスを付与し、Lint違反を0件にしています。
一方、GitHub Copilotは変数を誤ったRoleのdefaultsに配置し、実行時にエラーが発生しました。
一方で、GitHub Copilotが優れていた面もあります。
Task 7(デバッグ)では、CopilotがLintを完全にクリアしたのに対し、Claude CodeはLint違反が2件残りました。
また、Task 4 ではGitHub Copilotが冪等性を確保した一方、Claude Codeは確保できませんでした。
つまり、「どちらか一方が常に勝つ」のではなく、タスクの種類や複雑さに応じて得意不得意が異なるという整理の方が実態に近いです。
一方で、そのまま本番投入できるわけではなかった
両ツールとも、初稿としては十分な品質のコードを生成しました。しかし、実務でそのまま使うには課題も残ります。
- Lint違反が一部のタスクで残存する
- Roleの変数命名に揺れがある
- テスト環境の制約に起因するエラーを自律的に回避できないケースがある
- テンプレートファイルなどの補助ファイルが自動生成されないケースがある
- 採点基準の解釈が評価者間で揺れる場面があった
最後の点は、ツールの問題ではなく評価側の問題です。
冪等性のスコアリングにおいて、changed=0, failed=1 のケースを合格とするか不合格とするかで、個票間に解釈の不統一がありました。 この不統一を厳密に補正すると、一部のスコアが変わります。
こうした評価基準の曖昧さも、実際に回してみて初めて見つかるものでした。
カスタムインストラクション設計で分かったこと
今回の2回の評価を通じて、カスタムインストラクションの設計について、いくつかの実践的な知見が得られました。
効果があった指示
- per-task の become 適用:
- 条件Aでは両ツールが play レベルで一括適用していたが、条件Bでは両ツールが per-task に変更。明確かつ環境非依存な指示は確実に効く。
- Role変数プレフィックスの付与:
- Claude Codeは条件Aで7件あったLint違反を条件Bで完全に解消。ルールが具体的であれば遵守率が上がる。
- Docker環境制約の明示: 条件Aで
ansible.builtin.systemdを使っていたケースが、条件Bではansible.builtin.serviceに適切に変更された。
効果がなかった(不要だった)指示
- FQCNの必須指定: 条件Aの時点で両ツールともFQCN使用率100%。指示に含めても改善効果なし。
- shell/commandの禁止: 同様に、条件Aで両ツールとも使用率0%。追加の必要なし。
逆効果になった指示(初回評価時)
- 環境と適合しないモジュールの利用: テスト環境と適合しないモジュール利用を指示したことで、かえってエラーを引き起こしてしまった。(例:コンテナ環境でサポートされていないサービス起動の強制など)
ここから得られた教訓
カスタムインストラクションは、足せば足すほど良くなるわけではありません。 効果を出すには、以下の条件を満たす必要があります。
- 環境と整合していること: テスト環境や本番環境で実際に成立するルールだけを含める
- 改善余地があること: 既にモデルが自律的に達成している項目は省略または弱める
- 具体的であること: 抽象的な方針よりも、具体的なルール(プレフィックス名、使用するモジュール名など)の方が遵守されやすい
- 小さく検証すること: 全ルールを一度に追加するのではなく、段階的に追加して効果を確認する
AIエージェントは実務で使えるのか
今回の検証から見えてきたことを整理します。
初稿作成の高速化には十分使える
自然言語からPlaybookを起こす、既存スクリプトをAnsible化する、Role化のたたき台を作るといった用途では、両ツールとも実務上かなり有効でした。
特に、ゼロベースで構造を組み立てる最初の一歩は速くなります。
用途によって向き不向きがある
今回の評価からは、単純に「こちらが上」とは言えない結果が出ました。
| ユースケース | 傾向 |
|---|---|
| 単一Playbook作成 | 両ツール同等(同一コードを生成する場合もある) |
| Role構成を含む大規模な開発 | Claude Codeが優位(インストラクション遵守、変数管理の精度) |
| 既存資産のリファクタリング | 両ツール同等 |
| デバッグ・品質改善 | 両ツール同等(ややGitHub CopilotがLint品質で優位) |
| 組織ルールを反映した運用 | Claude Codeが優位(インストラクション効果の差が大きい) |
人の役割は減るというより、変わっていく
AIエージェントを使うと、単純な記述作業は減ります。一方で、人が担うべき役割はなくなりません。 むしろ、次のような役割の重要性が増します。
- 何を評価するかを決める
- 実行環境を整える
- 組織ルールを明文化する
- 結果の妥当性をレビューする
- 失敗要因を切り分ける
- 評価基準そのものの曖昧さを検出し、修正する
作業そのものよりも、評価設計や運用設計に人の判断が求められるようになる、というのが今回の取り組みを通じて得た実感です。
今回の取り組みで一番価値があったもの
今回の成果として、比較結果の数字そのものも意味はあります。
ただ、それ以上に価値があったのは、次の2点でした。
1. 再利用可能な評価フレームワークを作れたこと
- どの観点で評価するか
- どんなタスクを用意するか
- どうスコア化するか
- どのように結果を記録し、分析するか
こうした知見は、今後Ansible以外の題材を評価するときにも使えます。
たとえば 生成AIモデル、プログラミング言語バージョン、運用 Runbook 生成、設計書作成など、対象が変わっても評価の考え方は流用できます。
2. 評価フレームワーク自体の改善サイクルを回せたこと
初回の評価では、カスタムインストラクションが逆効果になるという想定外の結果が出ました。
しかし、その原因を切り分け、フレームワーク自体を改善し、再評価を実施したことで、カスタムインストラクションの効果を正しく測定できるようになりました。
この「評価して、問題を見つけて、評価系を直して、もう一度評価する」というサイクルを回せたことが、おそらく一番大きな収穫です。
AIエージェントの評価は、一度やれば終わりではありません。
評価基準が曖昧なら結果はぶれますし、テスト環境に不備があればツールの性能以外の要因でスコアが動きます。
評価フレームワーク自体を継続的に改善する仕組みを持つことが、実務適用に向けた土台になります。
おわりに
今回のプロジェクトを通して分かったのは、AIエージェント活用で本当に重要なのは、どのツールが強いかを一度きりで比べることではない、ということでした。
今回の取り組みで次の4点が重要であることを実感しました。
- 比較可能な評価フレームワークを先に作ること
- ツールだけでなく、環境と手順も含めて検証対象にすること
- 評価フレームワーク自体を改善し続けること
- カスタムインストラクションは環境との整合性を検証したうえで設計すること
AIエージェントは、実務の初稿作成や論点整理を大きく加速してくれます。
カスタムインストラクションを適切に設計すれば、組織ルールへの追従性も高められます。
一方で、品質と再現性を担保する仕組みまで自動で用意してくれるわけではありません。
今回の活動を通じて実運用に向けた「壁」も見えてきました。
たとえばデータセキュリティの観点では、顧客データや機密情報をどこまでAIに渡してよいのか、明確な線引き(データ分類基準)やマスク処理の仕組み化が不可欠です。
また、複数のエージェントを協調させる手法は強力な反面、大量のトークンを消費するため、日常業務への常用にはコストや費用対効果の慎重な見極めが求められます。
これらは今回の評価フレームワークとは別に、組織として基準を整備していく必要があります。
「AIを使うか・使わないか」ではなく、「組織として、どの条件なら安全かつ継続的に使えるか」という、私たちが次に向き合うべき重要なテーマです。
だからこそ、AIを業務に入れる前には、ツールの比較以上に、どう評価し、どう運用し、どう改善するかを設計する必要があります。
今回のAnsible評価は、そのための最初の一歩であり、同時に、改善サイクルを回す実践でもありました。
今後は、今回整備した評価フレームワークを土台として、別の題材や別のツールにも比較対象を広げていく予定です。
カスタムインストラクションの設計知見についても、今回得られた「環境との整合」「段階的な検証」という原則をもとに、さらに蓄積していきたいと考えています。
AIエージェントの活用は、ツールを選んで終わりではなく、「どう評価し、どう改善するか」を組織として設計するところから始まります。
今回の取り組みが、同じ課題に向き合っている方にとって何かのヒントになれば幸いです。

