AIで応対品質を自動評価。過去ログから「傾向分析・FAQ生成・回答のバラつき検知」までを一気通貫で行う手法
はじめに
カスタマーサポートやコンタクトセンターの現場では、日々膨大なチケット(メールやチャット等の問い合わせ履歴)が積み上がっています。
これらのテキストデータは本来、サービスの改善や応対品質向上のための「宝の山」ですが、実際には日々の返信対応に追われ、活用しきれていないのが実情ではないでしょうか。
「オペレーターによって返信内容や質にバラつきがある」
「新人のトレーニングに必要な『模範回答』が整備されていない」
「過去のログからFAQを作りたいが、分類・抽出する工数がない」
本記事では、こうした課題に対し、生成AIを活用して「過去の膨大な対応履歴」のみを起点に、品質改善(Quality Management)とナレッジ整備を同時に実現するアプローチをご紹介します。
特に今回は、一般的に必要とされる回答例や返信テンプレートが整備されていない状態からでも、AIが過去のやり取りから「模範応対」を推定し、評価やナレッジ生成を行う実践的な手法について解説します。
なお、やりとりするチケットをニアリアルタイムで分析することで、ケース単位での個別分析・感情分析データを組み合わせたスーパーバイザー(SV)への自動エスカレーション・オペレーターの成長を支援する自動フィードバックを行った事例については、こちらをご参照ください。
AI活用によるサポートケース評価の取り組み事例のご紹介
この記事でわかること
1. 膨大な過去チケットの「傾向分析」と「ナレッジ化」の自動化
どのような問い合わせ(Contact reason)が多いかを分類し、FAQや回答テンプレートの原案を自動生成する仕組み
顧客満足度(CS)を低下させた要因(アンチパターン)の抽出手法
2. オペレーターの「応対品質」を多角的に評価するロジック
初回応答での必須項目の確認漏れ(ヒアリング漏れ)がないか
マニュアルや公式ドキュメントを適切に引用・案内できているか(正確性・標準化)
オペレーター間での回答内容のバラつきがないか
3. 整備されたナレッジがない場合のAI活用アプローチ
過去のやり取りから「模範的な返信」をAIが推定生成し、それを基準に評価を行う手法
目的:暗黙知を可視化し、組織の資産へ
このプロジェクトの最大の目的は、サポート業務を単なるコストセンターから、顧客の声を製品改善に繋げ、組織に価値を還元する部門へと変革させることです。
本取り組みの大きな特徴は、既存の「ナレッジ(マニュアル等)が整備されていない状態」からでもスタートできる点です。
整理されたドキュメントがなくても、日々のログからまず傾向を掴み、そこからナレッジ化へと進め、準備コストをかけずに改善サイクルをスピーディーに回し始めることができます。
具体的には、以下の3つの実現を目指しています。
- ナレッジ活用状況の可視化: 担当者ごとの回答のばらつきや、根拠となるドキュメントの提示率を客観的な指標(KPI)で測る。
- 現場で即座に使えるFAQの生成: 過去の好事例から、再利用可能な「知識パッケージ」を抽出する。
- 応対アンチパターンの特定: 顧客の不満に繋がった失敗パターンを言語化し、再発を防止する。
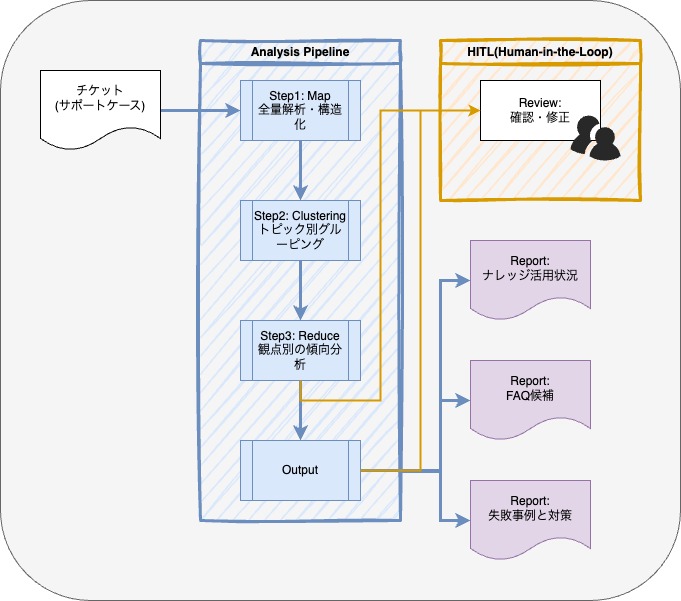
分析の全体フロー:4つのステップで知見を抽出・体系化
生成AI(モデルは Claude Sonnet 4.5 を利用)と独自のデータ処理フローを組み合わせ、以下の4段階でチケットを分析しています。
- Step 1: 全量解析と構造化 (Map):
- 全チケットを解析し、感情、重要度、問い合わせの意図などを構造化データに変換します。
- 以前の記事でご紹介した箇所です。チケットとその対応について評価した分析結果を利用します。
- Step 2: トピック別グルーピング (Clustering):
- 構造化データを「何に困っているか(Issue)」ごとにAIが分類、同一テーマ内での比較を行います。
- ユーザーが選択した「カテゴリ」に依存せず、問い合わせの中身(Issue)に基づいてAIが動的にグルーピングします。
- これにより、形骸化したカテゴリ設定や、「その他・全般」に埋もれてしまっていた真の課題を浮き彫りにし、実態に即した分析を可能にします
- Step 3: 観点別の傾向分析 (Reduce):
- 分類されたグループごとに、「ナレッジ活用」「FAQ」「失敗事例」の3つの軸で深掘り分析を行います。
- Step 4: 人手によるレビューと成果物化:
- AIの出力を人間が確認(Human-in-the-Loop)し、最終的な研修資料やFAQ記事として完成させます。
分析から得られる成果物(アウトプット)
本フレームワークを通じて、カスタマーサポートの現場で活用できる3つのアウトプットを生成しています。
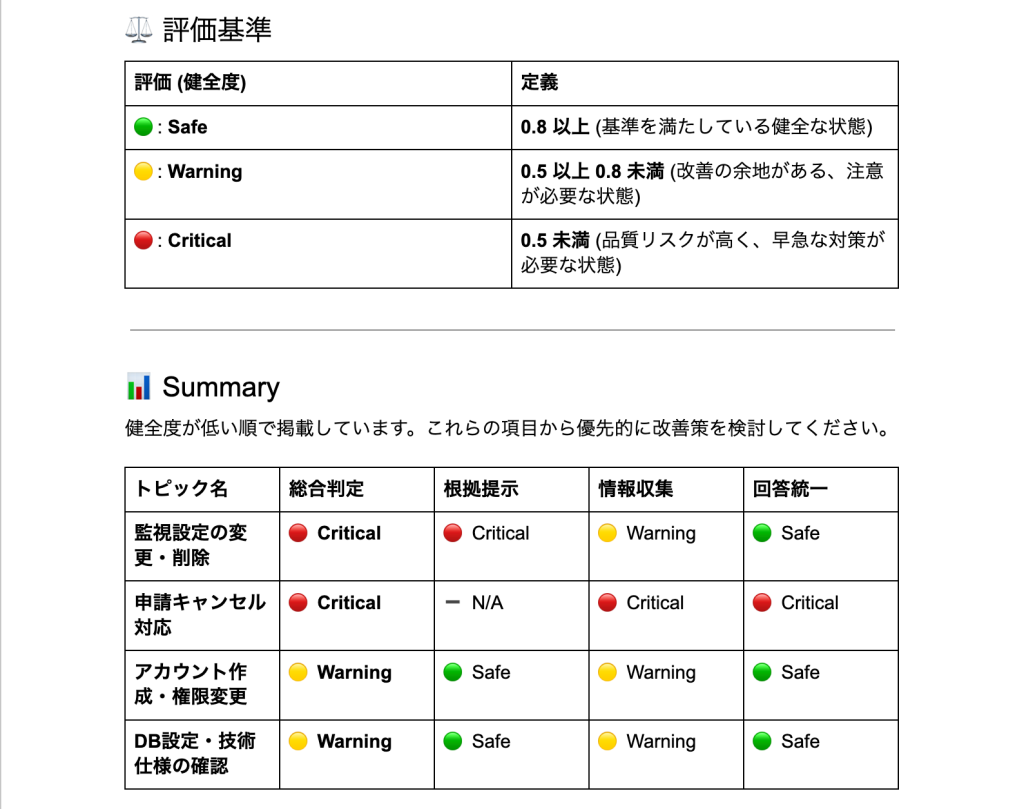
1. ナレッジ活用状況を可視化
組織全体で「知識がどれだけ正しく使われているか」を、客観的なデータで測定します。
本プロジェクトでは、組織の課題に合わせて様々な切り口でレポートの作成を行えるようにしていますが、今回は以下の3つの指標を使用しています。
- 根拠提示率: マニュアルや公式ドキュメントを適切に引用できているか。
- 必須情報の欠損率: 初回の応答で確認すべき情報の聞き出し漏れがないか。
- 回答ばらつき指数: 担当者間で案内手順や結論が揃っているか。
“ナレッジ活用状況” レポート例

2. 再利用可能な「知識パッケージとしてのFAQ」
単なるQ&Aではなく、模範的な解決手順をベースにしたFAQを作成します。
ユーザーが使う多様な言い回し(バリエーション)や、回答前に確認すべきチェックリストをセットにすることで、経験の浅いメンバーでもベテラン同等の回答が可能になります。
“FAQ候補” レポート例


3. 失敗から学ぶ「応対アンチパターンガイド」
顧客満足度を下げた「地雷フレーズ」や「誤認の兆候」を特定し、それに対する「推奨対応」を対比させて言語化することで、組織全体の対応品質を底上げします。
“失敗事例と対策” レポート例


精度と効率を両立する3つのアプローチ
本プロジェクトでは、大量の非構造化データを高精度かつ低コストで処理するために、主に以下の3つの工夫を取り入れました。
1. Map-Reduceによる大量データの正確な処理
生成AIに大量のデータを一度に読ませると、中間の情報を忘れてしまう現象(Lost-in-the-Middle1)が発生しがちです。
これを回避するため、データを適切なサイズに分割して並列処理(Map)し、その後に統合(Reduce)するアーキテクチャを採用しました。
これにより、スケーラビリティを確保しつつ、すべてのチケットを漏れなく評価対象としています。
2. 「基準選定」を挟む二段階分析
AIの出力が一貫性を欠くことを防ぐため、いきなり分析をさせるのではなく、まず「模範的な対応(Gold Standard2)」を選定するフェーズを設けました。
「何が良い回答か」という基準を固定してから各分析を行うことで、出力のブレを最小限に抑え、質の低い回答がナレッジ化されるのを防ぐ品質ゲートの役割も果たしています。
3. 現場の事実から逆算してナレッジ化
既存のドキュメントを検索させるのではなく、現場の「実際の対応履歴」からナレッジを逆算して生成しています。
担当者の暗黙知となっていた成功パターンを直接抽出することで、机上の空論ではない「生きた形式知」の構築を目指しました。
質の低いデータがナレッジベースに混入するのを防ぐ品質管理の役割も果たします。
最大の利点は、「分析のための事前準備(ナレッジ整備)が不要」であることです。
一般的なRAG(検索拡張生成)などの手法では、まず整備されたマニュアルが必要となりますが、本手法では「生のチケットログ」さえあれば分析を開始できます。
「ナレッジがない」状態からスタートし、まず現状の傾向をざっと掴んだ上で、そこから「ナレッジ化を目指す」アプローチが可能です。
AIの分析を支える「トレーサビリティ」の確保
「AIの分析結果はどこまで信頼できるのか?」という疑問に応えるため、トレーサビリティ(追跡可能性) の確保を重要視しています。
AIは単に「良い/悪い」のレッテル貼りをするだけでなく、その判定に至った 「根拠」を元の投稿内容から引用して提示します。
- IDによる紐付け: すべての分析結果に元のチケットIDを付与。
- エビデンスの抽出: 「なぜその対応が不適切なのか」の証拠となる発言をAIが抜粋。
これにより、「AIがそう言っているから」ではなく、「実際のデータを見て納得した上で」改善アクションを取ることができる仕組みを整えています。
まとめ
本記事では、AIを活用したサポートケースの品質・傾向分析の取り組み事例と、期待される効果、評価イメージをご紹介しました。
発展途上な部分はありますが、個人の頭の中にしかなかった「暗黙知」が「組織全体で活用可能な資産」となることを目指しています。
データに基づいた客観的な意思決定は、サポート品質の均一化だけでなく、新人教育の効率化や、メンバーがより高度な課題解決に集中できる環境づくりにも寄与しています。
「手元にログはあるが、分析のリソースがない」「まずは現状の品質を客観的に把握したい」といった課題をお持ちでしたら、ぜひお気軽にお問い合わせください。
[免責]
本記事の内容は、Blog投稿時点における投稿者又は弊社環境で確認している事象や手順です。
本件に伴い生じた不具合・損害等について、投稿者及び弊社は一切の責任を負わないものとします。
- Lost-in-the-Middle (中間の喪失) 長文の入力に対し、AIが最初と最後ばかりに注目し、中間に配置された情報を忘却・無視してしまう現象。[2307.03172] Lost in the Middle: How Language Models Use Long Contexts ↩︎
- Gold Standard (基準) AIの評価ブレを防ぐために、あらかじめ人間が作成した「模範的な正解データ」。 ↩︎

