SRE実践編 どのような取り組みを行うのか
SRE(Site Reliability Engineering)を一言で表すと「ソフトウェアエンジニアリングを軸に、フルスタックの迅速な継続的改善を、組織ぐるみ・組織横断で実現し続けること」です。
SRE(Site Reliability Engineering)の代表的なプラクティスは「SLI、SLA・SLO策定と運用」 「Error Budget策定と運用」 「Toil削減と50%ルール運用」 「ポストモーテム運用」 の4つです。
-
SLI、SLA・SLO策定と運用
-
システムの評価指標を策定し評価・運用する
-
-
Error Budget策定と運用
-
サービス品質の適正範囲を決定し運用する
-
-
トイル削減と50%ルール運用
-
トイル(後述)を削減し、50%以上の時間をエンジニアリング業務に充てられるようにする
-
-
ポストモーテム運用
-
インシデントを事後分析し学びを得る
-
これらを継続的・能動的に実践し、プロアクティブな運用文化を実現し浸透させます。
SREの実現はプラクティスを技術的に実践するだけでは不十分
SREの実現には 技術的観点 、 組織的観点 、 文化的観点 があります。
-
技術的観点の例:
<技術・プロダクト名>の導入 -
組織・文化的観点の例:
<人事・評価制度名>の導入
予算獲得やプロジェクト立案の視点では、技術的観点はわかりやすく取り扱いやすいものです。しかしSREの実現は技術的アプローチだけで充足できないものです。
まずは具体的な実装手法を挙げますが、ここではチラ見に留めます。具体的な実装手法の背景にある目的が重要です。このエントリでは前述の取り組み4つ「SLI、SLA・SLO策定と運用」 「Error Budget策定と運用」 「Toil削減と50%ルール運用」 「ポストモーテム運用」 が重要です。
技術的観点での具体的な実装手法のうち代表的なもの:
-
ソースコードリポジトリ整備導入と運用・改善
-
CI/CD導入と運用・改善
-
GitOps導入と運用・改善
-
ChatOps導入と運用・改善
-
モニタリングおよび自動対応導入と運用・改善
組織・文化的観点での具体的な実装手法のうち代表的なもの:
-
人事制度の変更・最適化
-
評価制度の変更・最適化
-
人事的配置の変更・最適化
-
組織設計の変更・最適化
-
1on1やメンター制度の導入と運用・改善
-
ペアプログラミング・ペアオペレーションやモブプログラミング・モブオペレーションの導入と運用・改善
-
内部勉強会の開催と運用・改善
SLI、SLA・SLOの策定と運用
システムの評価指標としてSLI、SLA・SLOを策定し評価・運用します。
SLI、SLA・SLOを策定し運用することで、システムにおけるもろもろの判断を理性的に・データをもとに行えるようになります。
-
SLI:Service Level Indicator
-
サービスレベルを表す指標(何の計測値をサービスレベルとして利用するか)
-
-
SLA:Service Level Agreement
-
システム利用者とのサービスレベルに関する合意
-
-
SLO:Service Level Objective
-
サービスレベルの実現目標
-
SLIはユーザにとってのシステムの価値を表す指標が適しています。多くの場合、まずはSLIとしてサービスのAvailability(可用性)を採用し、%で表します。
例:2021年10月のSLI実績値は99.995%
ここで “なにをもって(どの計測値がどうであれば)サービスがAvailだと言えるか” という点が議論になります。
Availability(可用性)という用語は伝統的にuptime(=稼働時間)を表してきました。機器の電源がONである時間が月のうちどの程度か、ネットワーク疎通可能な時間が月のうちどの程度か、HTTP応答可能な時間が月のうちどの程度か、といった具合です。
時間がベースのSLIの場合、例えば10月に応答不可能な時間が5分間あった場合は (1 − 20分間/(60分×24時間×30日))× 100=99.95% なのでSLIの実績値は99.95%です。
時間ベースの他にはカウントベース(例:総リクエスト中のエラーおよび遅延レスポンス数)や、カウントベースでの時間評価(例:エラーレートの閾値を設けたうえで1分単位で総リクエスト中のエラーおよび遅延レスポンス数を評価して0/1化し、月のうちOKな時間÷月の総時間×100)などがあります。
何をSLIとするのが適切かの判断には、システムの提供内容や開発体制など多くの要因が関わります。SLIは多くの要因から合議で決定されるものではなく、システムの責任者の意思のもとに決定されるべきものです。SLIは都度見直し更新していくものです。そのたびにシステムの世界観・価値観をより適切に反映したものになっていきます。
Error Budget策定と運用
サービス品質の適正範囲を決定し運用します。
値としてのError Buget(エラーバジェット)はSLOと100%の差です。
「Error Budget策定と運用」は「SLI 100%を目指さない意思決定と運用」とも言えます。
前提として『100%の信頼性を目標とすることは、基本的にいかなる場合も間違っている』と考えます(ただし心臓のペースメーカーや車のABSなど生命に直接的に大きく関わる場合は例外。いずれもSRE本より)。
SLIの値には “ちょうどいい塩梅” があるという考えです。
SLIはユーザにとってのシステムの価値を表しているので、SLI実績値が低いのであればユーザに価値を提供できていません。逆にSLIが高い場合は過剰品質の可能性があります。開発・運用の力(工数・時間など)は有限なので、SLIを高く保つことに力をかけるあまり、ユーザ価値創出が相対的に疎かになっているかもしれません。
ユーザ価値創出が滞るとそのぶんだけ競合システムの驚異が増し、市場相対的なシステムの価値が脅かされます。
データをもとに品質にかける力をちょうどいい塩梅に保つ手法がError Bugetの策定と運用です。
トイル削減と50%ルール運用
トイルを削減し、50%以上の時間をエンジニアリング業務に充てられるようにします。
※一般に時間の使い方を細かく計測することを強いるマイクロマネジメントは創造性を損なう最悪の施策なので概算で把握するにとどめ慣れればなりません。ただし自発的に自分のために計測するのであればその限りではありません
SRE本ではSREsの活動をトイル、オーバーヘッド(事務作業、人事関連作業、打ち合わせ、仕事のキュー整理、トレーニングなど)、ソフトウェアエンジニアリング、システムエンジニアリングに分類しました。
エンジニアリング業務の時間確保を阻む典型的なものはオーバーヘッドとトイル(Toil)です。ここではトイルに着目します。
『トイルとは、プロダクションサービスを動作させることに関係する作業で、手作業で繰り返し行われ、自動化することが可能であり、戦術的で長期的な価値を持たず、作業量がサービスの成長に比例するといった傾向を持つものです。』
『以下の1つ以上に当てはまるのであればその仕事のトイルの度合いは高い』
手作業であること
繰り返されること
自動化できること
戦術的であること
長期的な価値を持たないこと
サービスの成長に対してO(n)であること
『SREの報告によれば、SREのトイルの中で最も多いのは、割り込み(緊急ではない、サービスに関連するメッセージやメール)対応です。それに次ぐのがオンコール(緊急)対応であり、その次がリリース及びプッシュです。通常の場合、私たちのリリース及びプッシュのプロセスは、かなりの部分が自動化によって処理されますが、この領域ではまだまだ改善の余地が大きく残っています。』
(SRE本より)
このように、トイルは決して無駄な作業ではなく、なにがしかを成している作業です。自動化などによるトイルの削減は、現状維持の慣性・不安・慣例などを背景に「理論は賛成だが感情は反対」「総論賛成・各論反対」に陥りやすいです。
しかし “多すぎる” トイルはよくない未来をもたらします。トイルに追われると、キャリアの停滞、進歩速度の低下、トイルの増大などを招きやすくなります。エンジニアがトイルに追われオーバーヘッドに追われ満足にエンジニアリングできていない状況か続くようでは、そのエンジニアはじきに大きな不満を抱き、プロジェクトや組織を離れてしまうことでしょう。
エラーバジェットのことを思い出してください。過剰な品質は見えない鎖です。50%ルールを基準にしてトイルを許容可能な範囲に留めます。
ポストモーテム運用
インシデント(事件・事故)を事後分析し学びを得ます。
ポストモーテム(Postmortem)は検死や事後検討という意味です。
-
具体的な事象や状況
-
発生原因
-
発生した影響
-
発覚と対応の経緯
を分析し、
-
得た学び
-
同事象の再発防止策
-
横展開すべき具体策
を確認し、同種・類似のインシデント発生を未然に防ぐためにポストモーテムを行います。
運用しているどうしてもインシデントが発生します。
インシデントは残念なできごとですが、同時に貴重な学びを得られる機会でもあります。機会を活用するためにポストモーテムを行います。
ポストモーテムを行うときの鉄則は『Avoid Blame and Keep It Constructive(非難せず、建設的であること)』(SRE本より)です。
(直接的にだけでなく、間接的にであっても)関わる全ての人に以下のように行動しなければなりません。
-
客観的である
-
人ではなくできごとにフォーカスする
-
非難しない
-
謝罪しない
-
建設的であり続ける
誤りや不足を明確にすることだけを目的に指摘することは意味がありません。相手の状態に配慮し、非難せず課題を明らかにし、建設的に検討しなければなりません。
なお具体的な再発防止策は基本的に仕組みかソフトウェアエンジニアリングが軸になります。人間の教育や努力は必要不可欠ですが結果を担保する下支えにはなりません。
>関連記事
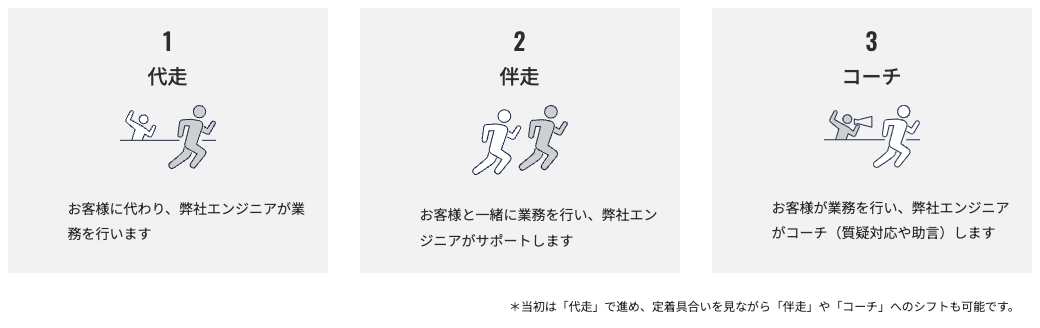
[PR] X-Tech5のSREサービスで『今日より、一歩前へ』
SREに取り組み始めたいものの、いまいち最初の一歩が難しいなぁという場合は、弊社X-Tech5のSREサービスをご検討ください。
まずは無料相談から!。直接ご支援・相談できます。
弊社エンジニアがSREとしてチームに参加し、チームの一員として動きSREを実現します。