2024年夏版:SRE入門編 SRE とは何か?コア技術と日本における事例や課題
この記事では、2024年夏時点の状況をもとに “そもそもSREとは何か?” “最近の日本でのSREの概況” “SREを支える技術とは?” “日本における事例とは?” について解説します。 2023年夏版と2021年秋版を踏まえて軽く経緯にも触れるので、この記事だけで十分に理解を得られると思います。
サマリー
-
SRE(Site Reliability Engineering)はDevOpsのいち実装形態であり、ユーザー価値を中心に据えた、サービスの保証側面である可用性、セキュリティ、パフォーマンス、持続性などを実現する取り組みです
-
ここ1年でSREの認知がさらに大きく広がりました。サービスの信頼性に目が向くひとが増えて、悩みを持つひとが増えたようです
-
システムやサービスごとにユーザー価値が多様なので、ユーザー価値を実現する取り組みであるSREも多様な事例がたくさんできています
-
裾野が大きく広がった結果として『いまの自分たちにとっての信頼性は何でどのくらい価値があるのか』よりも『これはSREなのか?』『これはSRE的にどうなのか?』を先に考えて悩んでしまうケースに多く遭遇するようになりました
-
当初のモチベーションの『チームで信頼性に向き合って高めていきたい』がいつのまにか『SREをやっていきたい』に変わっているケースが多いようです
→筆者はSREを独立した新規性の高い取り組みとして捉えるのではなくて、既存の信頼性実現の延長線上にある『より上手にユーザー価値とサービスの保証側面を実現する取り組み』と捉えることをお勧めしています
1.SRE (Site Reliability Engineering)とは何か
原義のSREを一言で表すと 「ソフトウェアエンジニアリングを軸に、フルスタックの迅速な継続的改善を、組織ぐるみ・組織横断で実現し続けること」 です。 2016年、O’Reilly Mediaから書籍『Site Reliability Engineering』(通称『SRE本』。日本語訳は翌2017年発売)が発売され、SREの考え方が世に広く紹介されました。

本書は、GoogleにおけるSRE(Site Reliability Engineering)とSREs(Site Reliability Engineers)の取り組みをまとめた書籍です。
Googleは「class SRE implements DevOps」とも言っており、SREはDevOpsの実践スタイルのひとつといえます。
また “システム開発者・運用者” から “サービス提供者” へのマインドチェンジを促していて、「ユーザーの期待・満足を、主要な評価・判断軸とする」「持続的成長に価値を置く」 といった点に斬新さを感じる人が多いようです。
1-1.『SRE本』での SRE
この『SRE本』で語られるSREの概要は以下で、正直なところSRE以前の一般的な運用現場からすると結構過激に思えます。
-
モチベーション: 複雑で大規模なコンピュータシステムを運用する際、システムの成長・拡大に比例してOps(運用系エンジニア)がどんどん増えていかないようにしたい
-
コンセプト: ソフトウェアエンジニアリングで、運用を再定義する
-
コアプラクティス: 伝統的オペレーションを行うOpsを全廃する
-
実現のためのアクション
-
ソフトウェアエンジニアがソフトウェアエンジニアリングを用いて伝統的オペレーション*を破壊・再定義・置換する
-
実現のために会社が、SREを支持・支援する
-
*伝統的オペレーション・・・手作業など、システムの成長・拡大に比例して手間や量が増える手法のこと。Sysadminアプローチとも呼ばれる
なお『SRE本』で言うところのReliability(信頼性)は以下のように定義されています。
信頼性とは「[システムが]求められる機能を、定められた条件の下で、定められた期間にわたり、障害を起こす ことなく実行する確率」です。
1-2.『SRE本』を飛び出した「それぞれの現場の SRE 」
多くの運用現場が、運用現場の管理者がSREのモチベーション(労働集約モデルからの脱却)に共感しました。
『SRE本』に続き多くの書籍が出版されました。どれもブ厚く、気軽に「最初から最後まで通読しましょう」と言えるようなボリュームではありません。「通読せねば!」ということはないですし、通読ありきはお勧めしません。
まずは第II部までのおよそ100ページを読み、以降は適宜読み進めるのをお勧めしています。
運用現場の多様性と、背景にある多くの課題や悩みを感じます。
『SRE本』を読んで、取り組んでみて、結果「Googleのビジネスモデルだからこそできたのだ」「Googleの財務状況だからこそできたのだ」「Googleの人材だからこそできたのだ」「GoogleのようなBigTechだからこそできたのだ」という感想を得るに至る事例も多く発生しました。
わたしが見聞きした範囲では、SREならではの事情はなく、「個人単位と組織単位で成長(=自己変革と行動変容)に不慣れなところが、プラクティスをなぞることで一足飛びに行動だけ変容しようとした」ケースがほとんどでした。
前回2023年夏の状況として「SRE」はハイプサイクルで言うところの幻滅期を乗り越え、アーリーマジョリティからレイトマジョリティが取り組み始め、いよいよ本格的な普及拡大期に入った感触があると書きましたが、2024年夏はその実感が非常に強くなりました。
SREに関連するイベントが数多く開催されています。
でキーワードに “SRE” を含むイベントの開催数を調べたところ以下のように激増しています。
-
2017年:63件
-
2018年:145件
-
2019年:125件
-
…
-
2022年:263件
-
2023年:298件
-
2024年:241件(7月末まで)
SREに関するコミュニティイベント SRE NEXT が2024年も開催されました。オンライン/オフライン合わせて1000人が集まる大きなイベントになっています。
2.[最近の]一般的な SRE
アーリーマジョリティ・レイトマジョリティが参加し場が混沌としてきたところで、2023年にGoogleが 『』 を公開しました。『SRE本』が547ページとハイボリュームなのに対して、『SREエンタープライズロードマップ』はたった56ページと短く、簡潔にポイントがまとまっています。

冒頭4ページの『第1章 エンタープライズSRE ことはじめ』から印象的なフレーズを抜粋します。
現状に関わらず、SREの導入で最も成功するのは、既存のフレームワークと真っ向から戦うのではなく、進化させ、補完することを選択した場合です
SREの実践はITILフレームワークと共存できる
結果が一致していてもやり方を調整する必要がある
DevOpsとSREの取り組みを両立させるためには、現実的であることが必要です
今いる場所から始める
SREは「人」から始まる
特定の組織で SRE を導入するベストプラクティスは 1 つではありません。正しい方法は、あなたが成功した方法だけです
どうでしょう。読んでみたくなってきましたか?
ちなみに、わたしが一番好きなところは
あなたのSREのバージョンが Googleのものと完全に一致する必要はありません。原則だけは一致させてください
です。
2-1.[最近の] SRE の一般的な期待値
『SREエンタープライズロードマップ』にもあるように、現状を勘案せずプラクティスをはめ込むのはアンチパターンです。
とはいえ一般的には「SREやってます」と言えば、以下を実現している、あるいは志向し・価値を置いて・実現に向けてそれなりに取り組んでいることを期待するでしょう。
-
ユーザーの期待・満足を、主要な評価・判断軸とする
-
ソフトウェアエンジニアリングする(再現性・再利用性の結果として、証跡確保・省略化・ミス削減などを狙う)
-
データドリブンで判断・行動する(観測を実現し(オブザーバビリティ )、観測結果を判断の前提にする。基本的にデータをもとに判断・行動する)
-
アジャイル的に取り組む(継続的・漸近的に改善を積み上げ進捗を生み出し、結果としての成果を狙う)
-
個人・組織の壁を作らない・壁を壊す・壁を超える
またこれらの背景には、以下のような文化・行動様式が前提となっています。
-
HRTを重視し遵守する(Humility:謙虚、Respect:尊敬、Trust:信頼)
-
心理的安全性を尊重する
-
検証し失敗し学ぶことを重視する
2-2.[最近の]組織での SRE の実現形態の例
最近は、実態としては従来のインフラエンジニアであっても、肩書・部署名としてSREを冠した職種や求人が主流になってきました。 募集要項(Job Description)はSREっぽくなっている場合もありますが、従来のインフラエンジニアとほぼ変わらないものも多くあります。
このあたりは資本力のある大手企業とそうでない企業との間で非常に乖離が大きいようです。 たとえば大手ではSoftware Engineeringやプロダクト開発経験を推奨事項でなく必須事項にしたり、その要求レベルを一般的なソフトウェアエンジニアと同等にしたりといった取り組みをしているところがありますが、一般企業ではSoftware Engineeringを要求しても評価側が評価できないという事態になっていたりもします。
認知が拡大し裾野が広がったことで、一般的な期待値と、現場での実現状況の中央値の乖離が大きくなっている ように感じます。
まず前提としてSRE(Site Reliability Engineering)は人や役割ではありません。SREの専門家・専任者を表す場合はSREs(Site Reliability Engineers)と表記します。
(とはいえSREが広まった結果として、厳密でない用語が広く多く使われるようになり、使い分けがなされないケースが増えています。個人的に残念ではありますが、新しい用語が広まったときの宿命でもあり、あまり目くじらを立てて界隈や業界の発展の足かせになるのもなぁと思っています)
ではSREは何かと言うと、SREは文化であり習慣です。
冒頭にも書いた通りSREの認知が広まったことにより 信頼性に悩みがある→ならばSREだ! という流れで、いまの自分たちにとっての信頼性の価値に十分に向き合わないままSREのプラクティスをつまみ食いして迷子になるケースが散見されるようになりました。結果としてSRE担当のSREsがいるかどうか、SREsが業務的に活躍しているかが評価指標になり、サービスの信頼性やユーザー価値に目が向かないまま上司も担当者も悩んでいる現場を見聞きします。
過渡期の成長痛を感じますね。
セキュリティやパフォーマンス、アクセシビリティなど一般に非機能要件と呼ばれる類の事柄は、専門性が必要なので専門家はいるものの、専門家だけが取り組むことではありません。SREも、専門家や特定の誰かがではなく、システムに関わる誰しもが取り組むことです。
とはいえ専門性を獲得するには専門家が必要ですし、新しい取り組みにおいて専任者がいると実現性や達成度が大きく向上するのも世の常です。
専門家や専門チームの配置、他のチームとの関わり方はいろいろなパターンがありプラクティス化されています。詳しくは以下の記事をご参照ください。
数ある発展形のひとつとして、最近はプラットフォームエンジニアリング(Platform Engineering)やインナーソース(InnerSource)が注目されています。いずれも “組織内のエンジニアリング能力や成果を組織全体で共有化し、全体最適化と持続的成長を図る” 取り組みです。
3.[最近の]コアプラクティスを支える技術の深化:モニタリングからオブザーバビリティへ
SREの一般的な期待値にある “データドリブン” を成すためにはデータが必要です。
SREのマインドは「ユーザーの期待・満足を、主要な評価・判断軸とする」「持続的成長に価値を置く」ですから、ここで言うデータは従前から扱われてきたシステムリソースの利用状況を表すシステムメトリクスだけでなく、サービスの稼働状況や実績を表すサービスメトリクス、結果としての事業成果を表すビジネスメトリクスなど多岐にわたります。
ユーザーの実際の利用状態を把握するためのRUM(Real User Monitoring)や、アプリケーションの実際の稼働状態を把握するためのAPM(Application Performance Monitoring)も重要なデータソースです。
このような、いわば次世代の拡大版モニタリングを指して オブザーバビリティ(Observability:可観測性) と呼びます。ユーザーサイドからバックエンドまで広く、本番環境でのアプリケーション動作状況をデバッグできるほど深い領域を対象に計測し、それらのデータを統合して一元的に把握・分析していきます。
詳しくは以下の記事をご参照ください。
SREの認知が拡大し裾野が広がった結果として 『オブザーバビリティツールを導入したけれど満足に活用できていない』 現場を多く見聞きするようになりました。筆者は本を書くくらいモニタリングやオブザーバビリティ領域が大好きでなのでこの状況が非常に残念です。このような状況を改善するサービスを提供していますので、心当たりの方はぜひご検討ください。
3-1.ユーザーの期待・満足を計測するSLI
ユーザーの期待・満足を計測するためにSLI(Service Level Indicator)を策定し計測します。典型的にはCUJ(Critical User Journey:サービスにおける超重要なユーザー行動)を軸にSLIを何にするか決断します。網羅性を気にするとSLIだらけになり指標としての能力がなくなってしまうので、主要なものを絞り込みます。
そしてSLIの達成目標であるSLO(Service Level Objectives)を決断し、日々の判断や行動の材料にします。典型的には「CUJがエラー無く快適に高速に利用できる時間帯が直近1ヶ月間で99%以上」などとします。
妥当なSLIとSLOは、信頼性への投資が不足していないか、過剰でないかの目安になります。 SLIやSLOだけを評価指標にするのは不十分です。これは過労のようにSLIやSLOにすぐに反映されない要素や、バックアップできていないなどの反映されたときには破滅するような大きなリスクをケアできないからです。しかし全く目安がないところからするとSLI/SLOという指標を持てることは大きな進歩です。
各種の経営指標と同じく『この指標が良好ならすべてが良好』と言い切れる指標はありません。個々の状況や時代に応じて指標自体も変化させていくべきものですから、指標を絶対視するのはうまい使い方ではありません。
また指標を目標や評価指標にすると、とたんに意義を失います。詳しくは「グッドハートの法則」で調べてみてください。
なおSLIやSLOは、SLAと語感が似ていますが別物です。SLAの決定には市場競争力や顧客調整などSLI・SLOにおいては直接的には関係のない力学が働きます。SLA決定の一要因としてSLIやSLOを考慮することはありえますが、SLI/SLOを支配的要因としてSLAを決定するとSLAの価値を損ないます。
3-2.持続的成長を計測するFour Keys
持続性成長のことを考えると、中長期での開発速度やサービス品質の維持向上は欠かせません。これらを支えるのは開発者体験(DX, DevEx:Developer eXperience)ですから、これらも計測しデータソースとします。
Four Keysと呼ばれる以下の指標群を計測することが多いです。
デプロイの頻度 – 組織による正常な本番環境へのリリースの頻度
変更のリードタイム – commit から本番環境稼働までの所要時間
変更障害率 – デプロイが原因で本番環境で障害が発生する割合(%)
サービス復元時間 – 組織が本番環境での障害から回復するのにかかる時間
Four Keysはソフトウェアデリバリーのパフォーマンスを計測するための指標です。 これらの指標が健全だということは、すなわちDevOpsを健全に回しやすい環境を実現し維持できていることを示しています。
4.[最近の]日本における SRE 事情と課題
SREの取り組みやSRE職について日本ではメルカリがアーリーアダプターの代表格です。メルカリは2015年にblogでSREチームの取り組みを公開しました。
2016年以降は、Webサービス提供会社を中心に、SRE職を設ける会社が増えました。 2024年にはVP of ReliabilityやVP of Platformを設ける会社を見かけるようになってきました。
日本では伝統的オペレーションによって解決する課題を担当していたのがインフラエンジニアであったことが多いため、もともとのフェーズによる区分け(Dev/Ops)ではなく、レイヤによる区分け(アプリケーションエンジニア/インフラエンジニア)で語られることが多いです。
2024年夏時点では某求人サイトで「インフラ」よりも「SRE」のほうが求人件数が多くなっています。 「インフラエンジニア」という項目・名称が消えつつあるという話もあります。
わたしたちX-Tech5も永らくを提供していますが、日系大手システムインテグレーター各社を含め多くの企業が「SRE」を冠する運用サービスを提供しています。
わたしの見聞きする範囲ではSREの取り組みを社内に広げる段階で難航することがままあり、その多くはSREに限った話ではなく、「大人が成長するのは難しい(成長=自己変革と行動変容)」「既存組織の枠組みをまたぐ取り組みが難しい」「他者に行動変容を促すのが難しい」「探索的な取り組みを承認・励行する仕組みや文化がない」ということのようです。
このあたりの取り組みについても前述の『』 で取り上げられています。読みたい理由がひとつ増えましたね。
4-1.非IT系の事業会社への取り組み拡大
筆者がSREの裾野の拡大として象徴的に感じるのはAEON(イオン)の取り組みです。
これらの取り組みはDX(Digital transformation)の文脈で語られることもありますが、食品や医薬品も扱うAEONの『信頼性』への取り組みがソフトウェアエンジニアリングの力で具体化・加速している様子が積極的に発信されています。
筆者は以前に不動産系の事業会社への信頼性向上を「SREと言わずに」取り組んでいました。SREを掲げると逆に迷子になりやすいので『信頼性』を柱に取り組むとスムーズにいきやすいように感じます。
4-2.盛り上がりを見せるPlatform Engineering
直接的にSREの一部というわけではないのですが、非常に近しい関連領域に Platform Engineering があります。 ざっくり言うと組織の開発生産性を高めるための横串での取り組みで、組織内のメンバーへの貢献を通じてユーザー価値を実現する取り組みです。
SREは直接ユーザー価値を意識して活動するのに対して、Platform Engineeringの直接の顧客は開発者などの社内メンバーだというのが大きな相違です。
また立ち位置が社内の制約としてのプラットフォームではなく選択肢としてのプラットフォームであること、目的がコスト削減ではなく組織のパフォーマンス向上であることなども相違点です。
コミュニティイベントが非常に盛り上がっており、Platform Engineering Kaigi2024はオンライン・オフライン合わせて1000人近い登録者となりました。
Platform Engineeringを語るうえではが基礎知識として、会話の土台としてよく参照されます。サービス開発組織のスタイルを考える上で非常に参考になるのでご一読をお勧めします。
Platform Engineeringはコストパフォーマンスの判断が非常に難しく、それなりに規模でないとガッツリとしたプラットフォームが価値を発揮するのは難しそうです。またガッツリとしたプラットフォームは基本的にボトムアップ/草の根で成していくものではないようで、現場と管理者の体感の違いや見え方、指標の違いがPlatform Engineeringに対する期待や取り組みの温度差になりすれ違いが多く発生しているように感じます。 小さな組織では小さなプラットフォームなど、プラクティスありきではなくそれぞれに適した形が必要ですね。
5.まとめ
-
SREを一言で表すと 「ソフトウェアエンジニアリングを軸に、フルスタックの迅速な継続的改善を、組織ぐるみ・組織横断で実現し続けること」
-
SREはDevOpsの実現形態のひとつ
-
SREでは「ユーザーの期待・満足を、主要な評価・判断軸とする」「持続的成長に価値を置く」
-
SREの実現形態はものすごく多様
-
主要な期待値のひとつに「データドリブンでの判断・行動」があり、それを支えるのがオブザーバビリティ(可観測性)
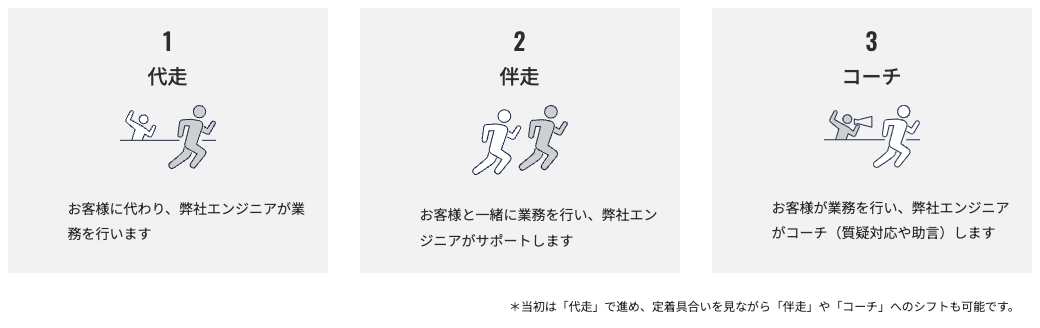
[PR] X-Tech5のSREサービスで『今日より、一歩前へ』
SREに取り組み始めたいものの、いまいち最初の一歩が難しいなぁという場合は、弊社X-Tech5のSREサービスをご検討ください。
まずは無料相談から!。直接ご支援・相談できます。
弊社エンジニアがSREとしてチームに参加し、チームの一員として動きSREを実現します。